- Overview
- Tutorials
- Getting started
- Get started with Canton and the JSON Ledger API
- Get Started with Canton, the JSON Ledger API, and TypeScript
- Get started with Canton Network App Dev Quickstart
- Using the JSON Ledger API
- Get started with smart contract development
- Basic contracts
- Test templates using Daml scripts
- Build the Daml Archive (.dar) file
- Data types
- Transform contracts using choices
- Add constraints to a contract
- Parties and authority
- Compose choices
- Handle exceptions
- Work with dependencies
- Functional programming 101
- The Daml standard library
- Test Daml contracts
- Next steps
- Application development
- Getting started
- Development how-tos
- Component how-tos
- Explanations
- References
- Application development
- Smart contract development
- Daml language cheat sheet
- Daml language reference
- Daml standard library
- DA.Action.State.Class
- DA.Action.State
- DA.Action
- DA.Assert
- DA.Bifunctor
- DA.Crypto.Text
- DA.Date
- DA.Either
- DA.Exception
- DA.Fail
- DA.Foldable
- DA.Functor
- DA.Internal.Interface.AnyView.Types
- DA.Internal.Interface.AnyView
- DA.List.BuiltinOrder
- DA.List.Total
- DA.List
- DA.Logic
- DA.Map
- DA.Math
- DA.Monoid
- DA.NonEmpty.Types
- DA.NonEmpty
- DA.Numeric
- DA.Optional
- DA.Record
- DA.Semigroup
- DA.Set
- DA.Stack
- DA.Text
- DA.TextMap
- DA.Time
- DA.Traversable
- DA.Tuple
- DA.Validation
- GHC.Show.Text
- GHC.Tuple.Check
- Prelude
- Smart contract upgrading reference
- Glossary of concepts
Runbooks¶
Runbooks are recipes that provide instructions for handling common issues or tasks. They are designed to be easy to follow and should include all necessary steps to resolve an issue.
PQS does not accept the passed in settings¶
Check if the argument in question is in the supported list of arguments by re-running the base command with:
--help/-hoption for command-line arguments--help-verbose/-Hoption for command-line arguments, environment variables and Java system properties
Check the settings for spelling and capitalisation.
Check if the argument supplied is applied and quoted in the configuration banner in the logs.
For example,
$ ./scribe.jar pipeline ledger postgres-document --source-ledger-host 10.0.0.0
should result in the following banner being displayed in the logs:
Applied configuration:
...
source {
ledger {
...
host=10.0.0.0
...
}
}
Adjusting PQS settings dynamically (at runtime)¶
PQS does not allow one to adjust any of its settings on the fly. Configuration settings along with the dynamically resolved parameters (party filters, packages, templates, etc) are fixed at the start of pipeline execution. Any change requires a restart, which should be fairly cheap under normal circumstances. You might also want to re-visit the configuration warning.
There is a suspicion that PQS is stalled¶
Check for ledger keep-alive output in the logs (frequency configured via --source-ledger-keepalive (default 40s)).
You should at least see this line repeated every 40s, even if there is no new activity on the ledger:
14:42:28.281 I [zio-fiber-600078685] com.digitalasset.zio.daml.Channel:37 Keep-alive (get ledger version) successful
If you expect data to flow, then check your filter configuration so that it’s not too restrictive (see Don’t see expected templates in PQS).
If all else fails, get your hands on a thread dump (for example, through diagnostics) and analyse it for any deadlocks.
Why might it take a long time before PQS starts processing streams?¶
The following phases happen during PQS startup:
fetching of all DARs from the ledger
parsing DARs locally to extract type information (cached locally for subsequent restarts)
converting type information into codecs
initializing DB tables and partitions corresponding to templates/interfaces and exercises
processing ACS if applicable
pipeline with ongoing processing starts now
Actual start-up time may be affected by multiple reasons, including, but not limited to:
slow network
excessive number of DARs/packages on ledger (not yet cached by PQS)
excessive number of new templates (likely caused by Daml upgrade/migration procedures)
the size of ACS (if applicable)
processing from early offsets (historical data) on a very lengthy ledger (will influence until PQS catches up to the head for ongoing streaming)
Don’t see expected templates in PQS¶
Check that your filter’s configuration is not too restrictive. Sanity check the overall count in INFO-level logs
Applied configuration:
...
pipeline {
filter {
contracts="*"
...
}
}
...
I [zio-fiber-330812857] com.digitalasset.zio.daml.ledgerapi.logFilterContents:12 Contract filter inclusive of 1 templates and 1 interfaces
Running logging at DEBUG level (--logger-level=Debug) will provide more detailed
information about specific templates included in the synchronization pipeline:
14:52:40.201 D [zio-fiber-655477872] com.digitalasset.zio.daml.ledgerapi.logFilterContents:13 Including template 5fe0c850054845d95a855650cba76d9d999c3e985ae549bcca01253b17b08b2c:PingPong:Ping
14:52:40.201 D [zio-fiber-655477872] com.digitalasset.zio.daml.ledgerapi.logFilterContents:13 Including template 5fe0c850054845d95a855650cba76d9d999c3e985ae549bcca01253b17b08b2c:PingPong:PingWithCK
14:52:40.201 D [zio-fiber-655477872] com.digitalasset.zio.daml.ledgerapi.logFilterContents:13 Including template 5fe0c850054845d95a855650cba76d9d999c3e985ae549bcca01253b17b08b2c:PingPong:Pong
Is it safe to change PQS --pipeline-datasource against the data store with existing data?¶
You might want to re-visit the configuration warning.
Debug output is too noisy¶
To prevent excessive output from Netty when the logging level is set to DEBUG, use the following arguments:
$ ./scribe.jar pipeline \
--logger-level=Debug \
--logger-mappings-io.netty=Info \
--logger-mappings-io.grpc.netty=Info
No data for a recently onboarded party¶
PQS is not notified of new parties, so it needs a restart to acknowledge the new party set.
Note that the best approach when onboarding new parties is to:
stop PQS from processing the data
onboard the new party
start PQS processing where it left off
Otherwise, there is a chance of corrupting PQS data for the newly onboarded party if party onboarding happens during the active PQS pipeline.
If a new party was onboarded without stopping the PQS pipeline, it is best to either:
purge the PQS database and re-ingest the data either from
Genesisor fromLatest(see Ledger streaming & recovery), orperform a reset from a particular offset (before the offset of the first event with the new party involved) by following the instructions
The list of parties in the current pipeline session is output in the logs on startup:
15:01:40.872 I [zio-fiber-950510203] com.digitalasset.zio.daml.ledgerapi.PartiesService:61 2 known parties retrieved
15:01:40.876 I [zio-fiber-950510203] com.digitalasset.scribe.pipeline.pipeline.Impl:39 Starting pipeline on behalf of 'Alice::12209adab9c5e9d672d7b4515e26f4cd296cc2ec99bdb9787be7e804c49ca52f2686,Bob::12209adab9c5e9d672d7b4515e26f4cd296cc2ec99bdb9787be7e804c49ca52f2686'
PQS complains it cannot start due to various offset mismatches¶
PQS may fail to start due to a non-reconcilable gap in the events history (potentially caused by ledger pruning or other factors). Please, refer to these 2 sections for additional insights:
In most likelihood, under normal conditions, PQS should be launched with the following arguments, unless there is a strong reason to modify them:
$ ./scribe.jar pipeline --pipeline-ledger-start=Oldest --pipeline-ledger-stop=Never
Please, refer to the logs for the steps of determination, which offset is being selected to start the pipeline
15:28:12.778 I [zio-fiber-1984883840] com.digitalasset.zio.daml.ledgerapi.StateService:79 Retrieved ledger end offset: 00000000000000000f
15:28:12.809 I [zio-fiber-1984883840] com.digitalasset.scribe.pipeline.pipeline.Impl:91 Last known checkpoint is at offset '00000000000000000f' and index '9'
15:28:12.811 I [zio-fiber-1984883840] com.digitalasset.scribe.pipeline.pipeline.Impl:100 Continuing from offset '00000000000000000f' and index '9' until offset 'INFINITY'
Is it safe to restart PQS? Can data get corrupted?¶
PQS was designed with failure friendliness - it does not require graceful shutdown or draining of active tasks. It is absolutely fine if the JVM process gets killed. On a restart, PQS will perform a clean-up procedure of data beyond the current watermark and then re-subscribe and continue processing from the watermark’s offset onwards (see Recover).
What happens if multiple PQS instances are launched against the same data store?¶
In case multiple PQS instances are launched against the same data store, no data corruption happens. However, they will be competing among themselves to become the exclusive writer, so it might affect the throughput of ledger stream consumption. It is unadvisable to do so (see also High availability).
Which metrics are available? How to integrate them?¶
PQS Docker images are published with the preconfigured Prometheus endpoint (see Observe). By default,
it listens on 0.0.0.0:9090, so it is expected to be hooked into existing monitoring infrastructure.
To that extent, PQS releases are accompanied by dashboards that can be imported into a Grafana instance for convenient visualisation of application health.
It is highly advised to implement an observability platform in your environment. While logs help troubleshoot correctness issues, metrics are much more suitable for performance related troubleshooting.
PQS processing throughput seems low¶
PQS had been benchmarked against high throughput scenarios of up to 100K+ events/sec. PQS processing pipeline is just an intermediary between two data systems - ledger (Canton) and relational database (Postgres), so most likely to troubleshoot such a cause, one would need to dig into one of these endpoints.
Suggested areas of attention (see also Optimize):
ledger
host/OS-level metrics - CPU, I/O, RAM, etc (look for resource saturation)
check with Canton for relevant metrics
Postgres
check minimum resources requirements for Postgres
check host/OS-level metrics - CPU, I/O, RAM, etc (look for resource saturation)
configuration settings and non-default overrides
metrics according to database (
pg_stat_statements,pg_stat_activity)
PQS
check minimum resources requirements for PQS to avoid unexpected imbalance
check host/OS-level metrics - CPU, I/O, RAM, etc (look for resource saturation)
ensure these settings are not set too low (i.e. no less than defaults)
--source-ledger-buffersize--target-postgres-buffersize--target-postgres-maxconnections(because parallel processing which affects both throughput and latency is tied to this configuration)check vital metrics look good (PQS metrics dashboard and how to read it)
Dissecting the logs¶
PQS emits a healthy volume of relevant information while running into stdout stream. INFO level describes
application-level events such as:
ledger keep-alives
lifecycle information
authentication events
starting conditions - offsets, current watermark, etc
ingress of ledger events
conversion of payloads
watermark advancement
DEBUG and TRACE levels add supplementary troubleshooting information. Caution needs to be exercised since
increasing the log level might affect performance negatively along with exposing sensitive data (contract’s contents,
for instance).
PQS metrics dashboard and how to read it¶
PQS Dashboard is designed to read from top to bottom. It provides information from general to more specific, so it is good practice to scan through the dashboard as it goes and spot anomalies along the flow.
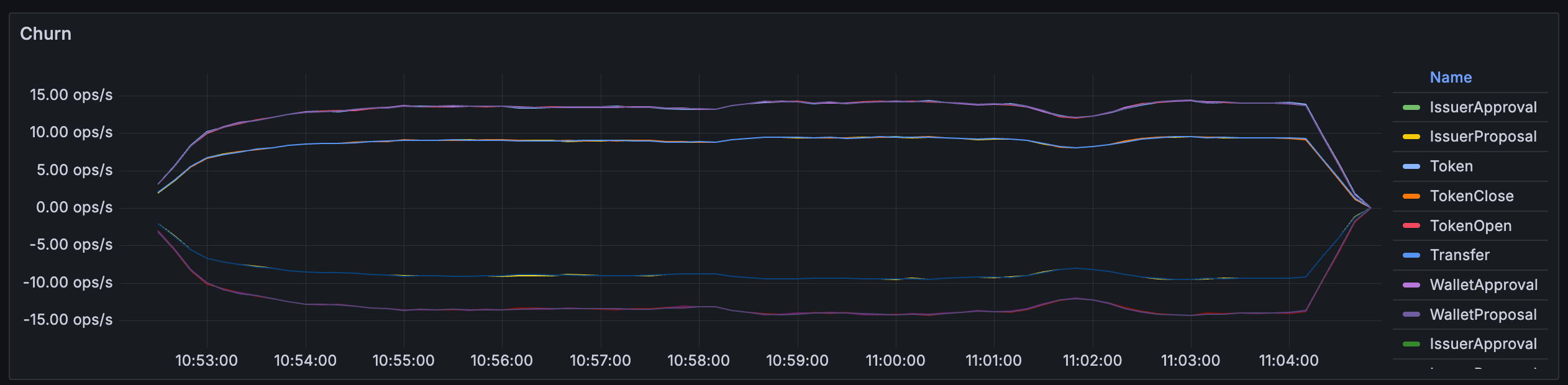
Contracts > Churn¶
Per-template activity (creates/archives) on the ledger. This chart may be useful to gauge relative throughputs in business terms.
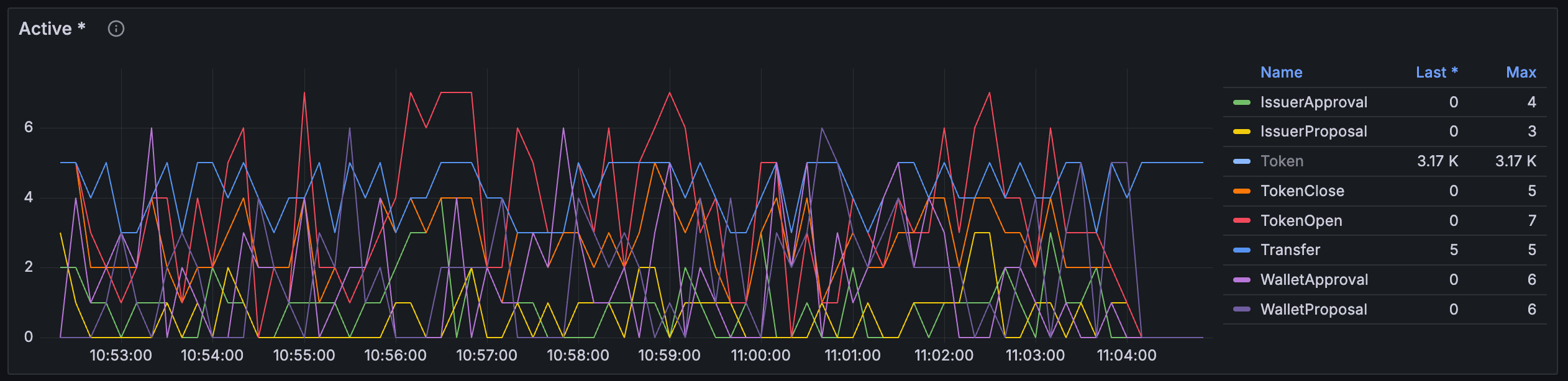
Contracts > Active¶
Per-template active contracts count. This chart may be useful to gauge composition of ACS
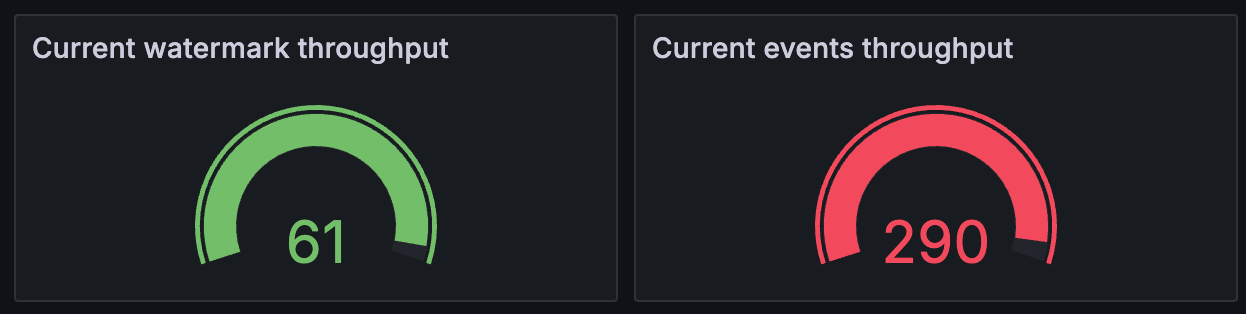
Throughput > Throughputs¶
Current throughputs in terms of watermark advancement and stored events
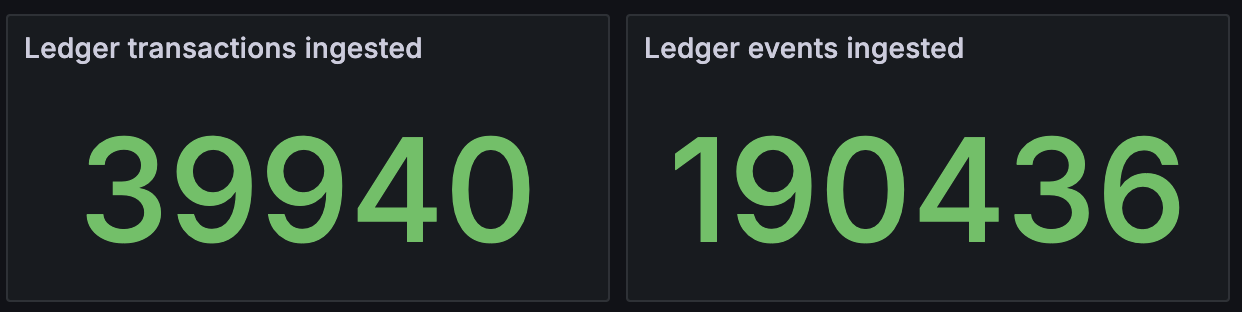
Throughput > Ingested counts¶
Total counts (as measured in transactions and events dimensions) since latest PQS start
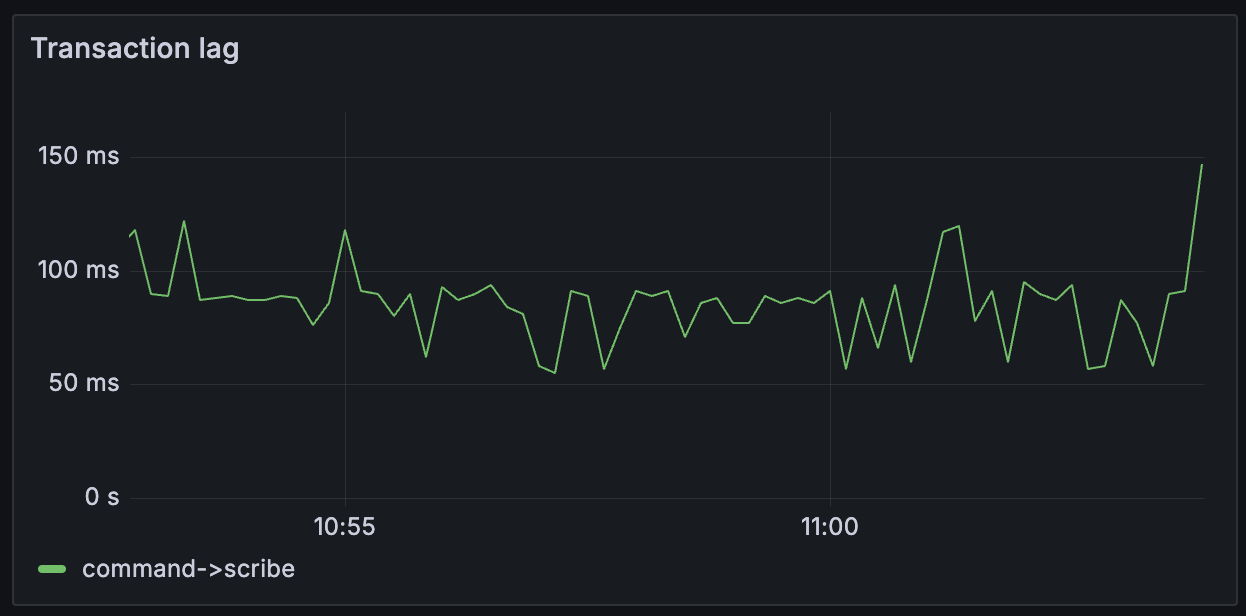
Throughput > Transaction lag¶
Tracks lag from ledger (delta between command completion determined by transaction’s effective_at attribute and
ingestion by PQS pipeline as determined by wall clock). This is latency introduced by upstream processes outside of
PQS control (Ledger API, network, etc). This chart indicates, for example, that 100 ms of latency has already been
contributed to the overall end-to-end processing latency:
Throughput > Watermark history¶
Time series of watermark progression throughput. This manifests the rate of ledger transactions becoming available for querying with PQS Read API functions. The typical shape of the chart is shown below. For uniform traffic it should represent smooth curves.
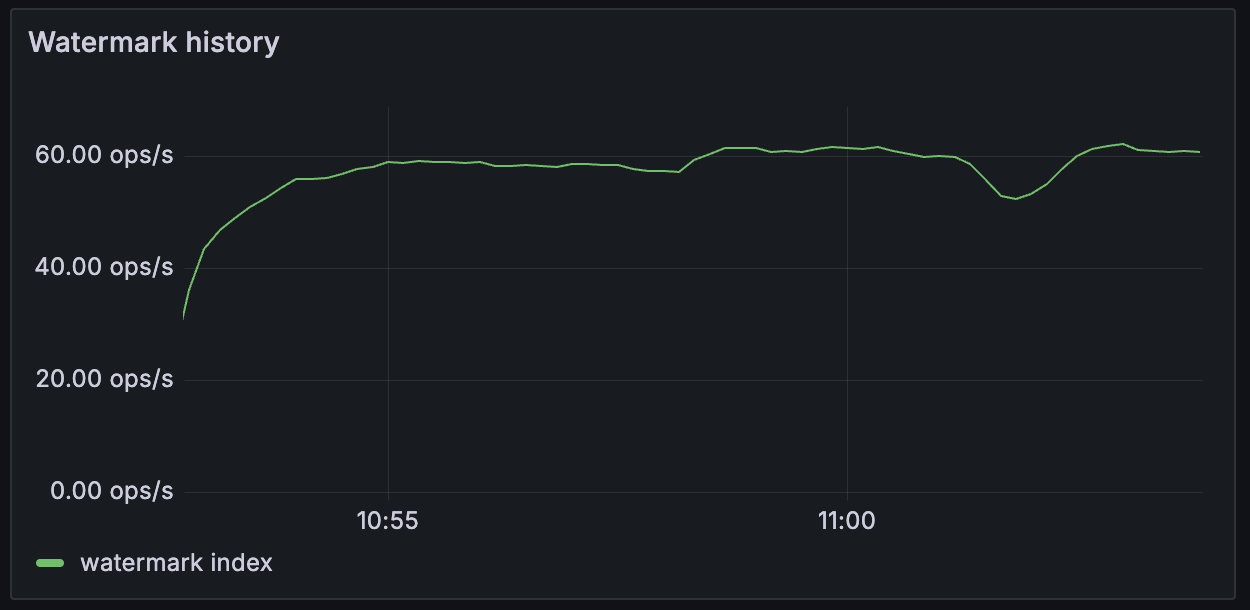
Anomalies might include torn shapes and zigzag patterns with inactivities followed by spikes.
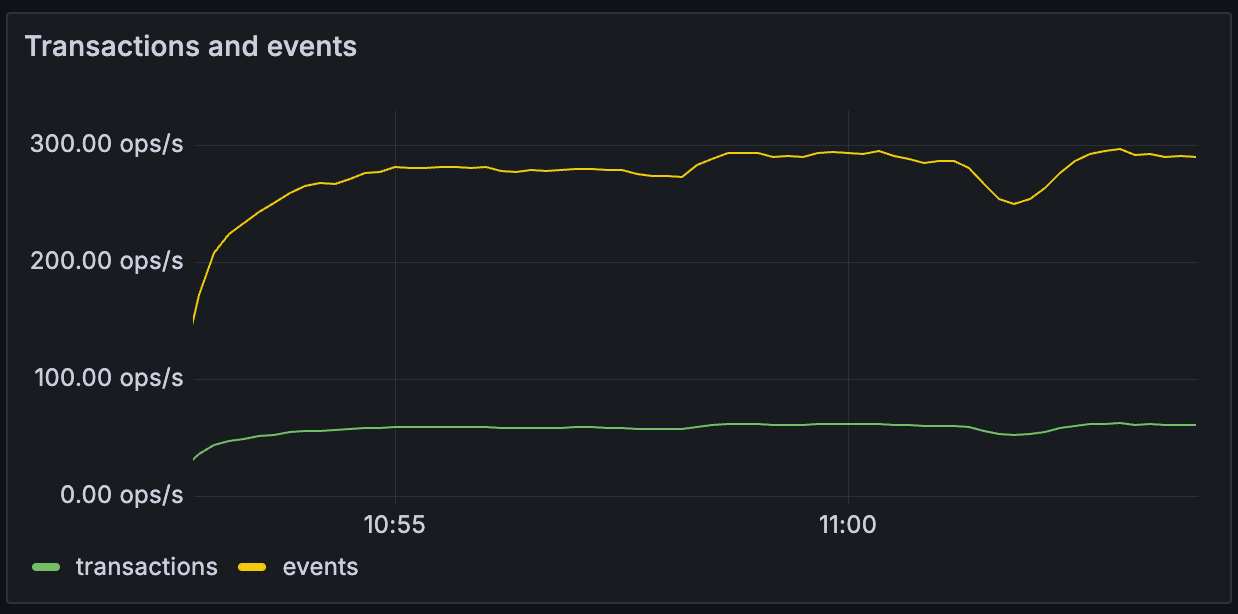
Throughput > Transactions and events¶
The shape of ingested traffic in terms of transactions and events dimensions. Provides an idea of the coarseness of transaction sizes.
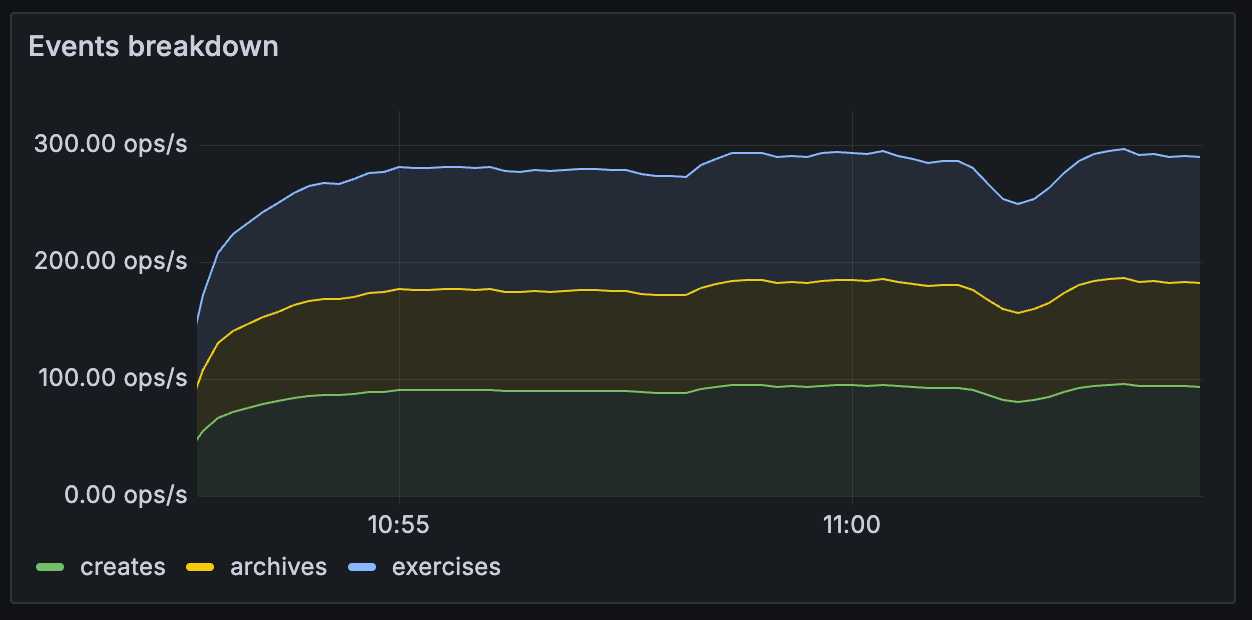
Throughput > Events breakdown¶
Provides breakdown of event types inside transactions (contents differs depending on pipeline source - flat transaction vs transaction tree)
Throughput > Waitpoints - ACS / streaming¶
ACS = only during seeding from the ActiveContractSet Ledger API service
streaming = normal processing pipeline
The internal pipeline is composed of distinct stages separated by queues (aka wait points). This chart indicates throughputs of items passing through them. Note that items might be distributed and consolidated at various stages, therefore relative throughputs can differ between the stages even for streamlined flow.
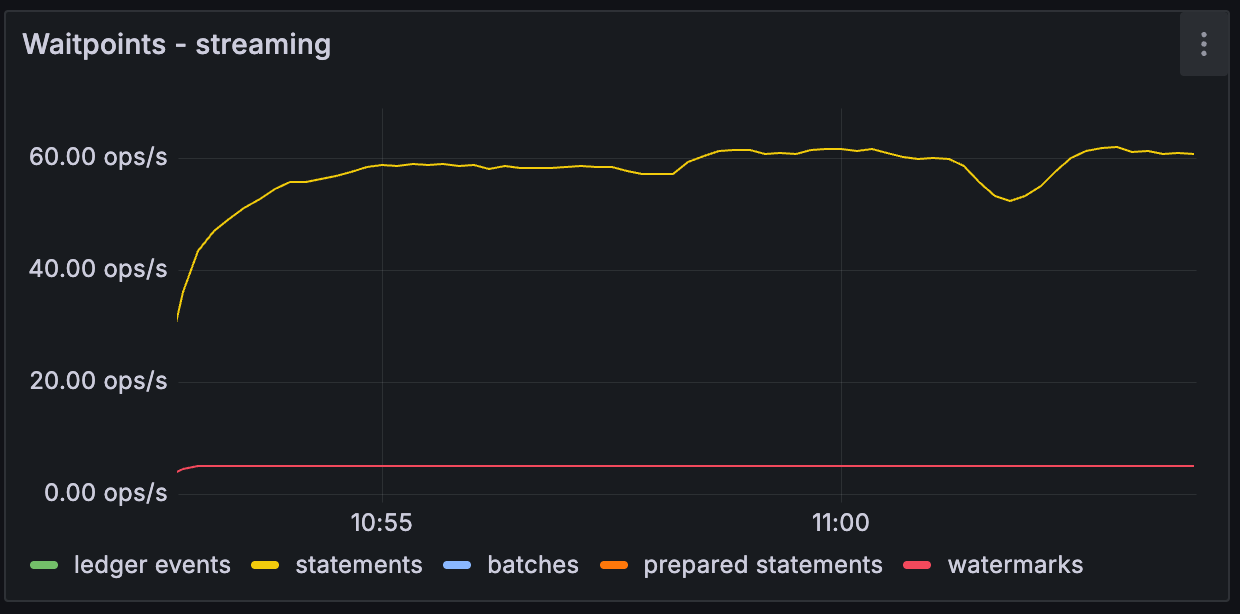
Anomalies here might include change in relative throughputs indicating non-uniformity of neighbouring transaction sizes at certain points. This might indicate noisy neighbours potentially causing latency spikes for other transactions.
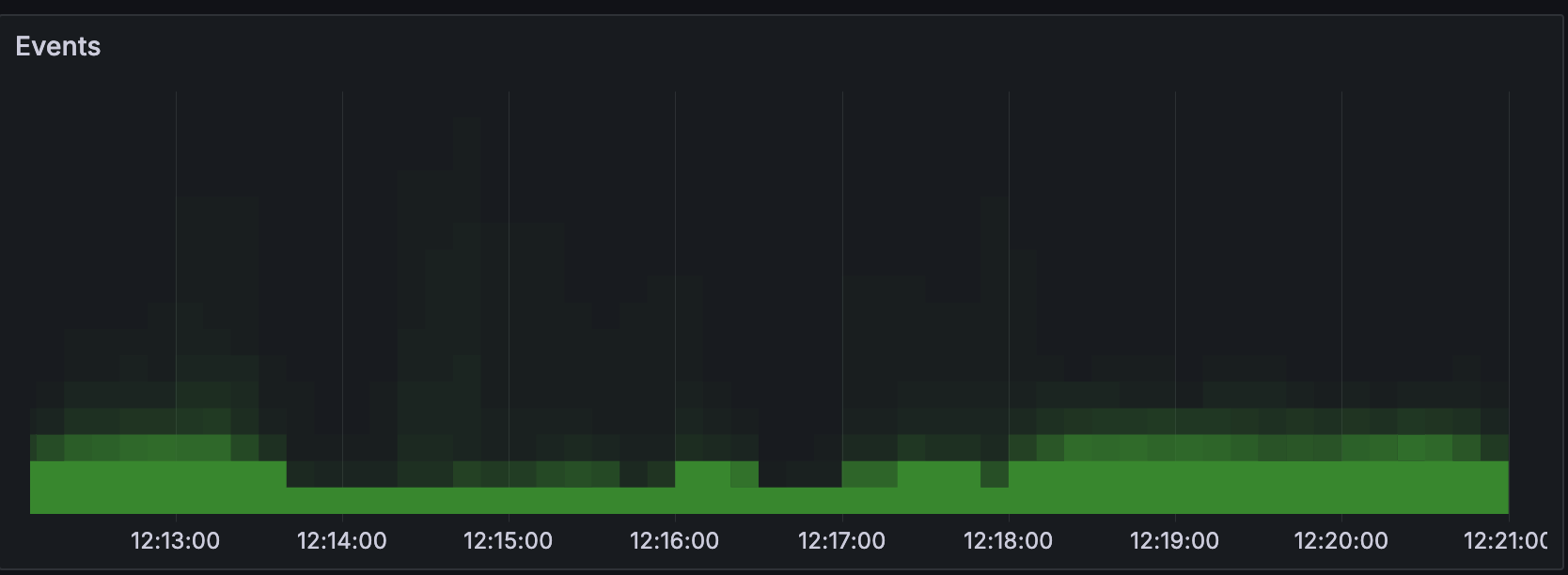
Queue sizes¶
Time-series of histograms (vertical slices) that represent queue size of named wait points. Bottom all-green line indicates queue was empty all the time and this represents healthy situation without queueing or back-pressuring:
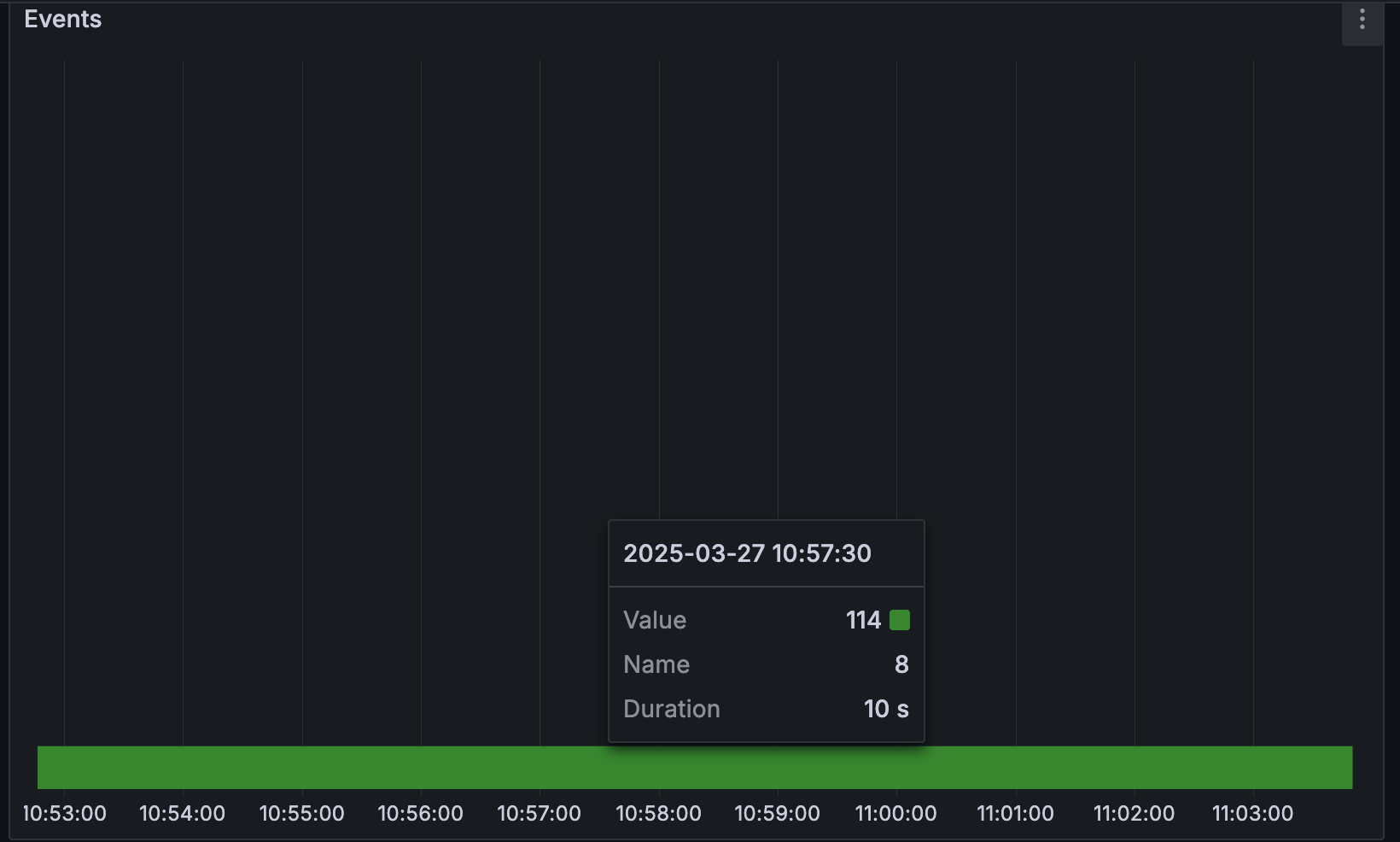
Below is a case where queueing was present due to downstream backpressure. This should be a matter of interest and suggests further investigation. Queue sizes are arranged cascadingly and the point at which queue size becomes empty points to a bottleneck, because pushback is propagated upstream.
Latency¶
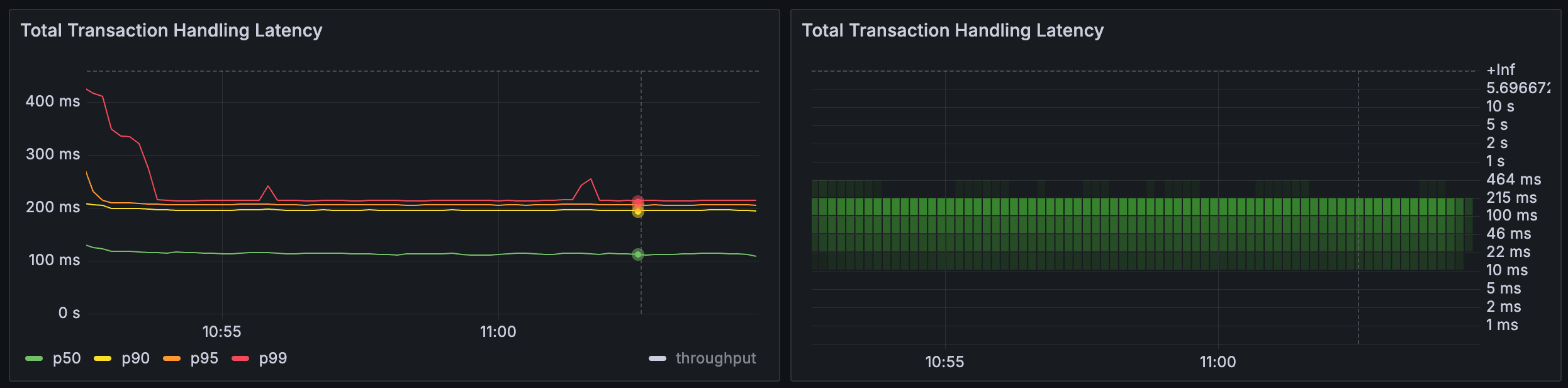
Time taken to transfer a unit of work between wait points with different levels of granularity. Provides a percentile-based view as well historical histogram heatmap.
In this chart we can observe from the left panel that the majority of operations take less than 10 ms with some outliers taking up to 30 ms. On the right chart we see more detailed insights, namely, there are two dominating operations with average latencies 1 ms and 5 ms each.
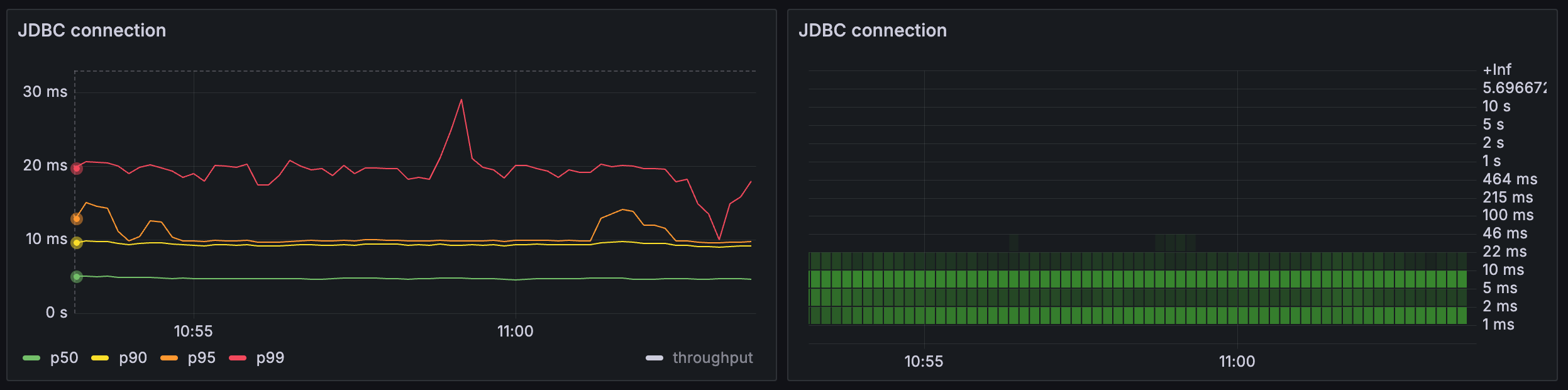
Anomalies might include huge differences between p50 and p95 percentiles. As well as non-uniform spread of latencies in the right part.
Slowly increasing latencies across a lengthy time slice should cause concerns of service degradation.
Latency > Total Transaction Handling Latency¶
Time taken by the entire PQS pipeline between receipt from Ledger API to being committed to Postgres.
JVM Metrics¶
Provides a series of metrics that are common across any JVM application in terms of memory management, CPU utilisation and garbage collection activity. The most crucial signals to monitor and interpret are:
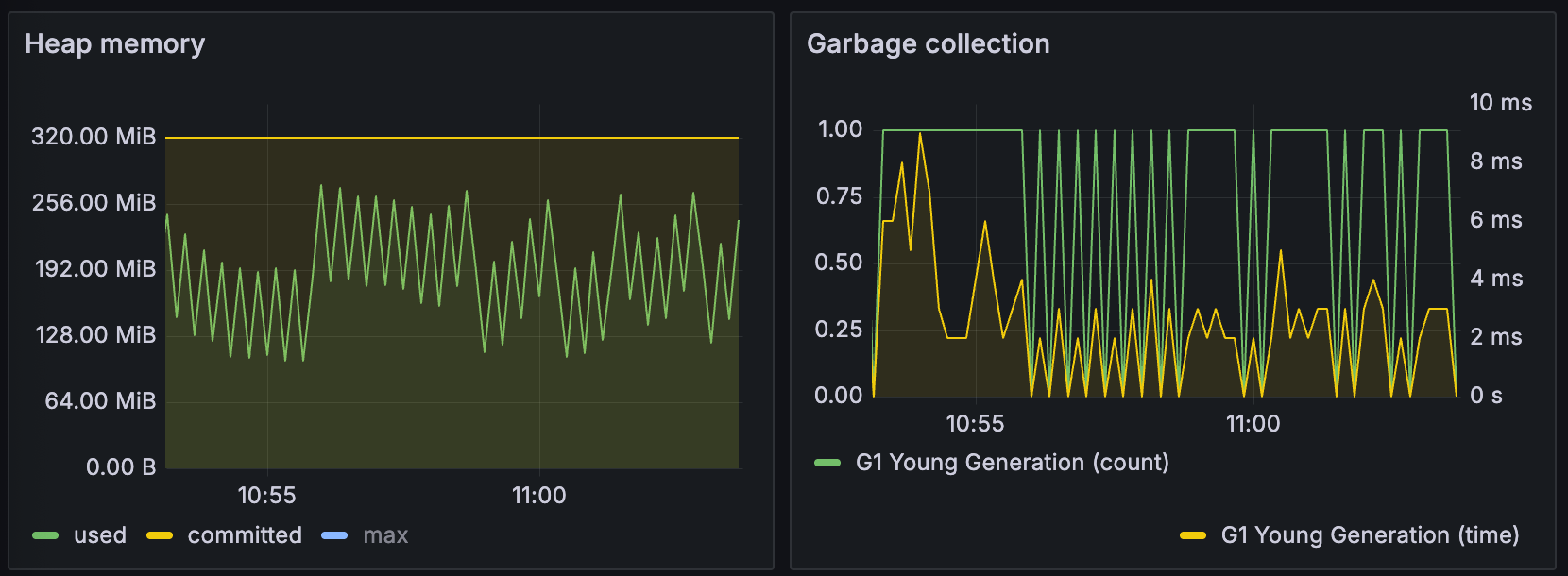
Anomalies might include used approaching committed and never decreasing. At the same time garbage collection
frequency and time taken are increasing. These are the symptoms that out of memory conditions are imminent. If these
parameters look healthy but PQS still exists with 137 exit code, then most likely a supervisor (Docker,
Kubernetes) is terminating PQS forcefully - investigate potential configuration imbalance. Make sure that JVM
memory-related settings are applied.
SQL queries useful for troubleshooting¶
It is highly recommended that Postgres metrics are captured through appropriate tools (like postgres-exporter) and shipped into metrics storage (like Prometheus) for historical trends identification and analysis. The following visualisations useful for analysis would be possible for creation:
In the absence of integration into metrics storage, one can run the following queries when necessary for point-in-time view.
Statistics on disk vs index I/O¶
select stat.relname as relname,
seq_scan,
seq_tup_read,
idx_scan,
idx_tup_fetch,
heap_blks_read,
heap_blks_hit,
round((100 * heap_blks_hit::float / coalesce(nullif(heap_blks_hit + heap_blks_read, 0), 1))::numeric, 2) as heap_blks_ratio,
idx_blks_read,
idx_blks_hit,
round((100 * idx_blks_hit::float / coalesce(nullif(idx_blks_hit + idx_blks_read, 0), 1))::numeric, 2) as idx_blks_ratio
from pg_stat_user_tables stat
right join pg_statio_user_tables statio on stat.relid = statio.relid;
Look for rows whose heap or index ratio diverge from 100 but the number of reads or scans is significant.
Currently executing queries¶
select pid,
datname,
usename,
application_name,
client_hostname,
client_port,
backend_start,
query_start,
(now() - query_start) as exec_time_so_far,
query,
state
from pg_stat_activity
where state = 'active';
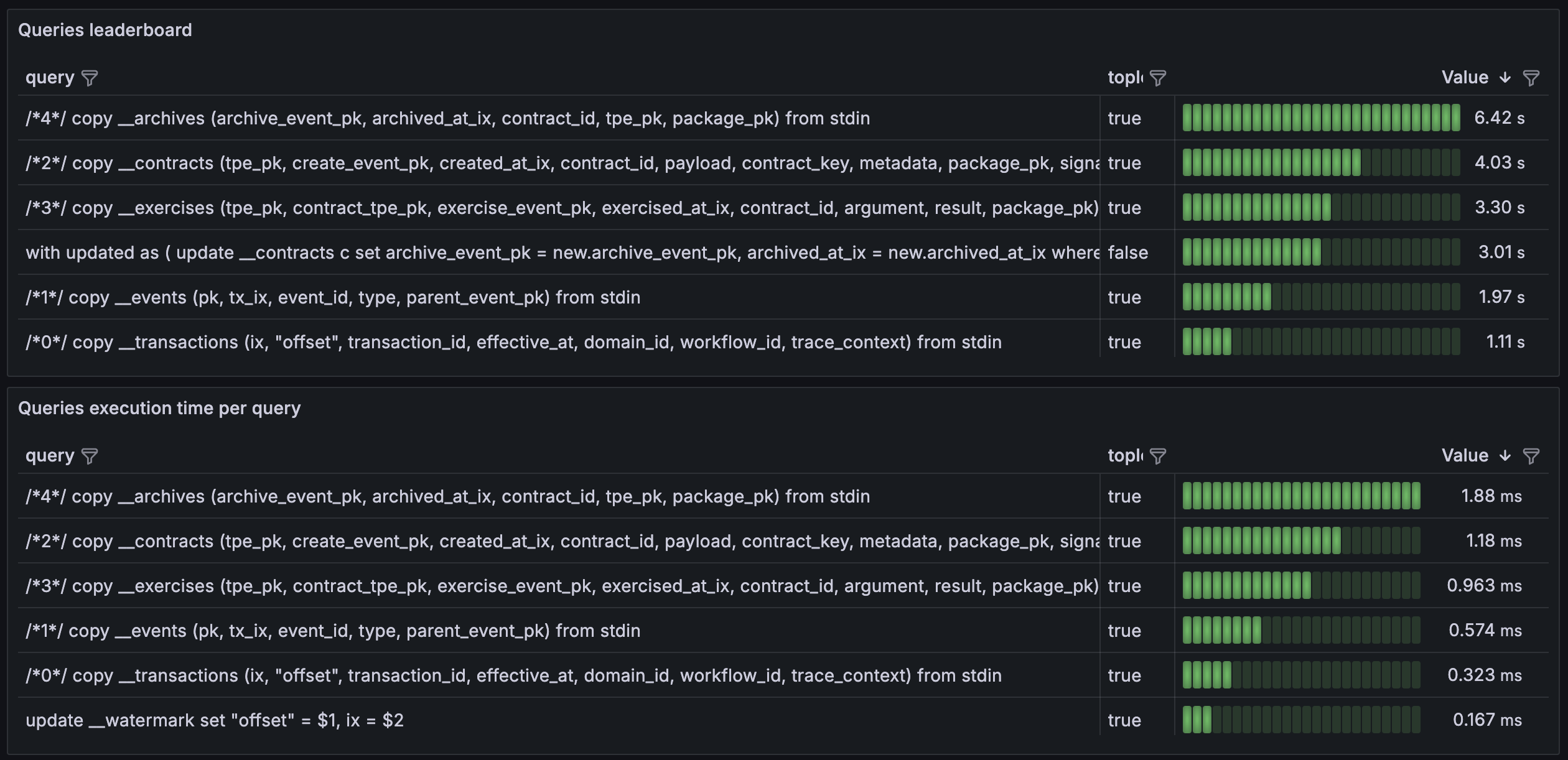
Top 10 queries by run time¶
This query requires pg_stat_statements
extension installed into PostgreSQL.
select total_exec_time,
calls,
query,
queryid,
toplevel
from pg_stat_statements
where not (
query ilike 'create %' or
query ilike 'alter %' or
query ilike 'drop %' or
query ilike 'grant %' or
query ilike 'revoke %' or
query ilike 'set %' or
query ilike 'do %' or
query like '%pg_stat%' or
query like '%pg_database%' or
query like '%pg_replication%' or
query like '%information_schema%' or
query like '%prune_contracts%' or
query like 'with deleted_transactions%' or
query like 'with deleted_contracts%' or
query = 'SELECT version()' or
query = 'SELECT $1' or
query = 'BEGIN' or
query = 'COMMIT' or
query = 'ROLLBACK'
)
order by total_exec_time desc
limit 10;
All non-empty tables rows count¶
select schemaname, relname, n_live_tup as rows_in_table
from pg_stat_user_tables
where n_live_tup > 0
order by rows_in_table desc, relname;
Table data in cache per table¶
select *
from (select relname,
heap_blks_read as disk_blocks_read,
heap_blks_hit as buffer_hits,
round((100 * heap_blks_hit::float / coalesce(nullif(heap_blks_hit + heap_blks_read, 0), 1))::numeric, 2) as cache_hit_ratio
from pg_statio_user_tables
order by cache_hit_ratio desc) as foo
where cache_hit_ratio > 0;
Index data in cache per table¶
select *
from (select relname,
idx_blks_read as disk_blocks_read,
idx_blks_hit as buffer_hits,
round((100 * idx_blks_hit::float / coalesce(nullif(idx_blks_hit + idx_blks_read, 0), 1))::numeric, 2) as cache_hit_ratio
from pg_statio_user_tables
order by cache_hit_ratio desc) as foo
where cache_hit_ratio > 0;
bgwriter frequency¶
select total_checkpoints,
seconds_since_start / total_checkpoints / 60 as minutes_between_checkpoints
from (select extract(epoch from (now() - pg_postmaster_start_time())) as seconds_since_start,
(checkpoints_timed + checkpoints_req) as total_checkpoints
from pg_stat_bgwriter) as sub;
Total sizes of tables¶
select n.nspname as "schema",
c.relname as "name",
case c.relkind
when 'r' then 'table'
when 'v' then 'view'
when 'm' then 'materialized view'
when 'i' then 'index'
when 's' then 'sequence'
when 't' then 'toast table'
when 'f' then 'foreign table'
when 'p' then 'partitioned table'
when 'i' then 'partitioned index' end as "type",
pg_catalog.pg_get_userbyid(c.relowner) as "owner",
case c.relpersistence
when 'p' then 'permanent'
when 't' then 'temporary'
when 'u' then 'unlogged' end as "persistence",
am.amname as "access method",
pg_catalog.pg_size_pretty(pg_catalog.pg_table_size(c.oid)) as "size",
pg_catalog.obj_description(c.oid, 'pg_class') as "description"
from pg_catalog.pg_class c
left join pg_catalog.pg_namespace n on n.oid = c.relnamespace
left join pg_catalog.pg_am am on am.oid = c.relam
where c.relkind in ('r', 'p', '')
and n.nspname <> 'pg_catalog'
and n.nspname !- '-pg_toast'
and n.nspname <> 'information_schema'
and pg_catalog.pg_table_is_visible(c.oid)
order by 1, 2;
Total sizes of indexes¶
select n.nspname as "schema",
c.relname as "name",
case c.relkind
when 'r' then 'table'
when 'v' then 'view'
when 'm' then 'materialized view'
when 'i' then 'index'
when 's' then 'sequence'
when 't' then 'toast table'
when 'f' then 'foreign table'
when 'p' then 'partitioned table'
when 'i' then 'partitioned index' end as "type",
pg_catalog.pg_get_userbyid(c.relowner) as "owner",
c2.relname as "table",
case c.relpersistence
when 'p' then 'permanent'
when 't' then 'temporary'
when 'u' then 'unlogged' end as "persistence",
am.amname as "access method",
pg_catalog.pg_size_pretty(pg_catalog.pg_table_size(c.oid)) as "size",
pg_catalog.obj_description(c.oid, 'pg_class') as "description"
from pg_catalog.pg_class c
left join pg_catalog.pg_namespace n on n.oid = c.relnamespace
left join pg_catalog.pg_am am on am.oid = c.relam
left join pg_catalog.pg_index i on i.indexrelid = c.oid
left join pg_catalog.pg_class c2 on i.indrelid = c2.oid
where c.relkind in ('i', 'i', '')
and n.nspname <> 'pg_catalog'
and n.nspname !- '-pg_toast'
and n.nspname <> 'information_schema'
and pg_catalog.pg_table_is_visible(c.oid)
order by 1, 2;
Largest contract instances by payload size¶
select template_fqn,
contract_id,
octet_length(payload::text)::bigint as size_in_bytes
from active()
order by size_in_bytes desc
limit 10;
Largest transactions by payload size¶
select created_at_offset,
sum(octet_length(payload::text)::bigint) as size_in_bytes
from creates()
group by created_at_offset
order by size_in_bytes desc
limit 10;
Largest transactions by events count¶
select "offset",
count(*) as events_in_tx
from __events, __transactions
where __events.tx_ix = __transactions.ix
group by "offset"
order by events_in_tx desc
limit 10;